TL;DR Here’s the link to the project.
Have you ever been curious about how databases work under the hood? I certainly was and decided to roll up my sleeves and implement one from scratch. In this blog series, I’ll be sharing my experience implementing Bitcask in Rust and discussing some of the techniques I used to make it goes blazingly fast. So if you’re ready to dive deep into the world of high-performance data storage, buckle up and let’s get started!
Bitcask? I hardly know her…
If you’re looking for high-performance, production-ready embedded key-value storage, you may want to check out Bitcask. It’s one of the most efficient options available and was created as the storage engine for the distributed database Riak. The creators of Riak described Bitcask as “A Log-Structured Hash Table for Fast Key/Value Data” meaning that Bitcask writes data sequentially to an append-only log file and uses an in-memory hash table to keep track of the positions of its log entries.
What’s so great about this design decision is that it allows Bitcask to achieve incredibly high read/write throughput while still being easy to implement. If you’re interested in learning more about the design of Bitcask and how some of its core components work, keep reading! We’ll dive into the details and show you how you can implement them for yourself.
Data files
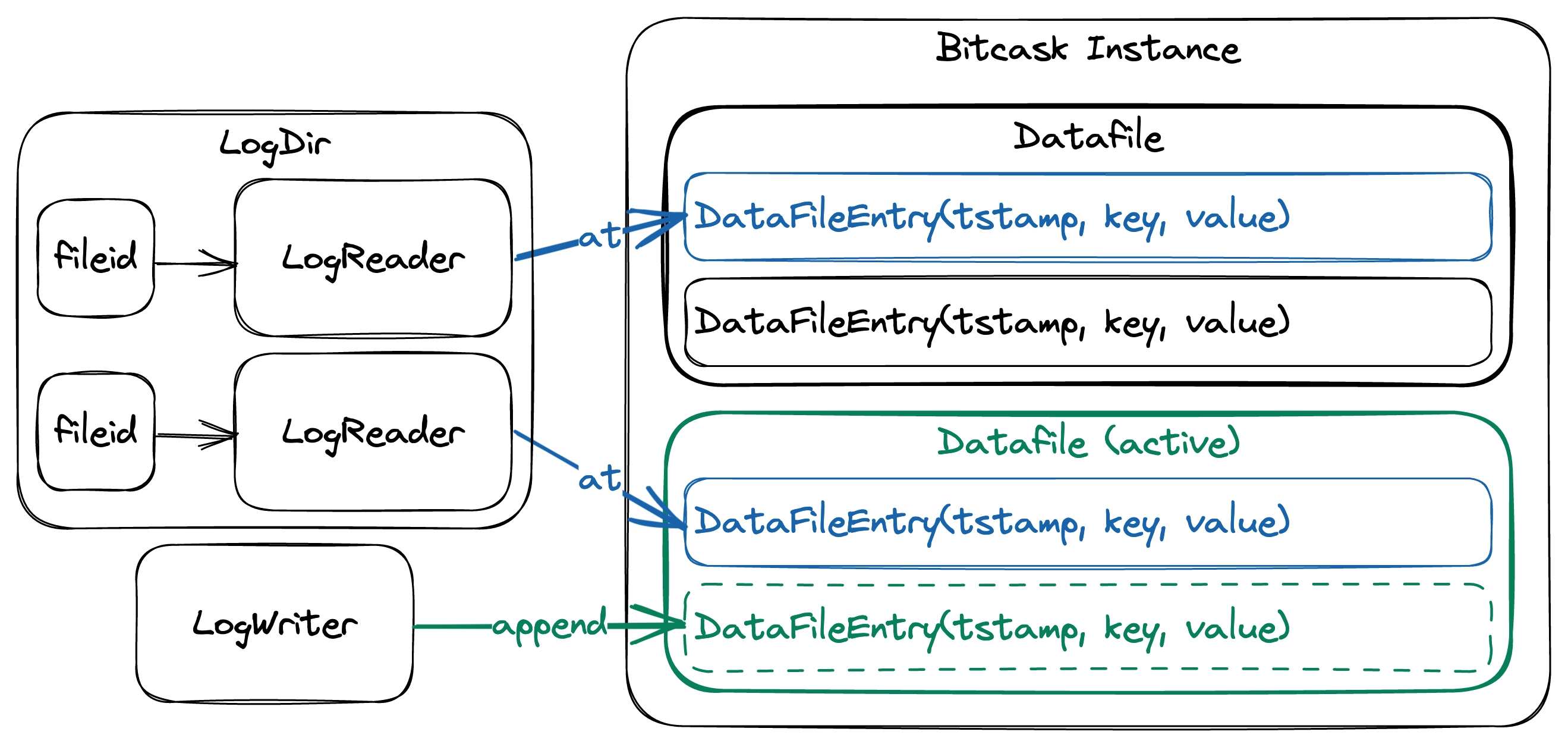
Writing and reading files
A Bitcask instance uses many data files, but only one can be active at any given moment. Each file is assigned a unique identifier that increases monotonically so all data files can be sorted by their creation order. The active file is writable and append-only, while closed files are immutable and read-only. All operations that mutate the data store are translated into entries in the active data file. When the file’s size meets a certain threshold, it’s closed, and a new one is created.
We define a structure to represent a data file entry, which includes the timestamp of when it was created, the key, and the value. One important decision to make is which serialization format to use. Our implementation utilizes bincode and serde for serializing and deserializing log entries instead of using the custom encoding scheme described by the original paper. Furthermore, we use Bytes from the bytes library for a fast bytes buffer implementation.
#[derive(Serialize, Deserialize)]
struct DataFileEntry {
tstamp: i64,
key: Bytes,
value: Option<Bytes>,
}
We introduce a structure called LogWriter to serialize data file entries and append them to the end of a file. Once we’ve appended a log entry to the file, we’ll return a LogIndex that tells us the length and position of the serialized data file entry.
impl LogWriter {
fn append<T: Serialize>(&mut self, entry: &T) -> Result<LogIndex, Error>
}
struct LogIndex {
len: u64,
pos: u64,
}
We implement the LogReader structure to efficiently read data file entries given their serialized length and position. By leveraging memmap2, LogReader can directly access file segments without excessive file seeking. The function for obtaining a data file entry is LogReader::at and is marked as unsafe. The reason is that memmap2 creates a buffer that maps directly onto the file, which can lead to certain risks. For example, we can access an invalid segment that does not exist within the file, and race conditions can happen when multiple threads or processes attempt to read from or write to the same file simultaneously. Although we take measures to prevent race conditions within our storage engine process, we acknowledge that calls to LogReader::at will always have inherent risks since external processes may modify the data files in ways we can’t control.
impl LogReader {
unsafe fn at<T: DeserializeOwned>(&mut self, len: u64, pos: u64) -> Result<T, Error>
}
Recall that Bitcask is essentially a directory containing many data files. As such, we define a structure that can manage this directory and serve as a primary access point for all read operations. The LogDir structure contains the mappings between a fileid and the LogReader that reads the corresponding data file. We use an LRU cache to store the mappings so we can control the number of open file descriptors, preventing the system from reaching its maximum limit. If we were to instead use a HashMap, we might accidentally exceed the maximum open file descriptor limit, and the program would likely crash.
struct LogDir(LruCache<u64, LogReader>);
impl LogDir {
unsafe fn read<T, P>(&mut self, path: P, fileid: u64, len: u64, pos: u64) -> Result<T, Error>
where
T: DeserializeOwned,
P: AsRef<Path>
}
KeyDir
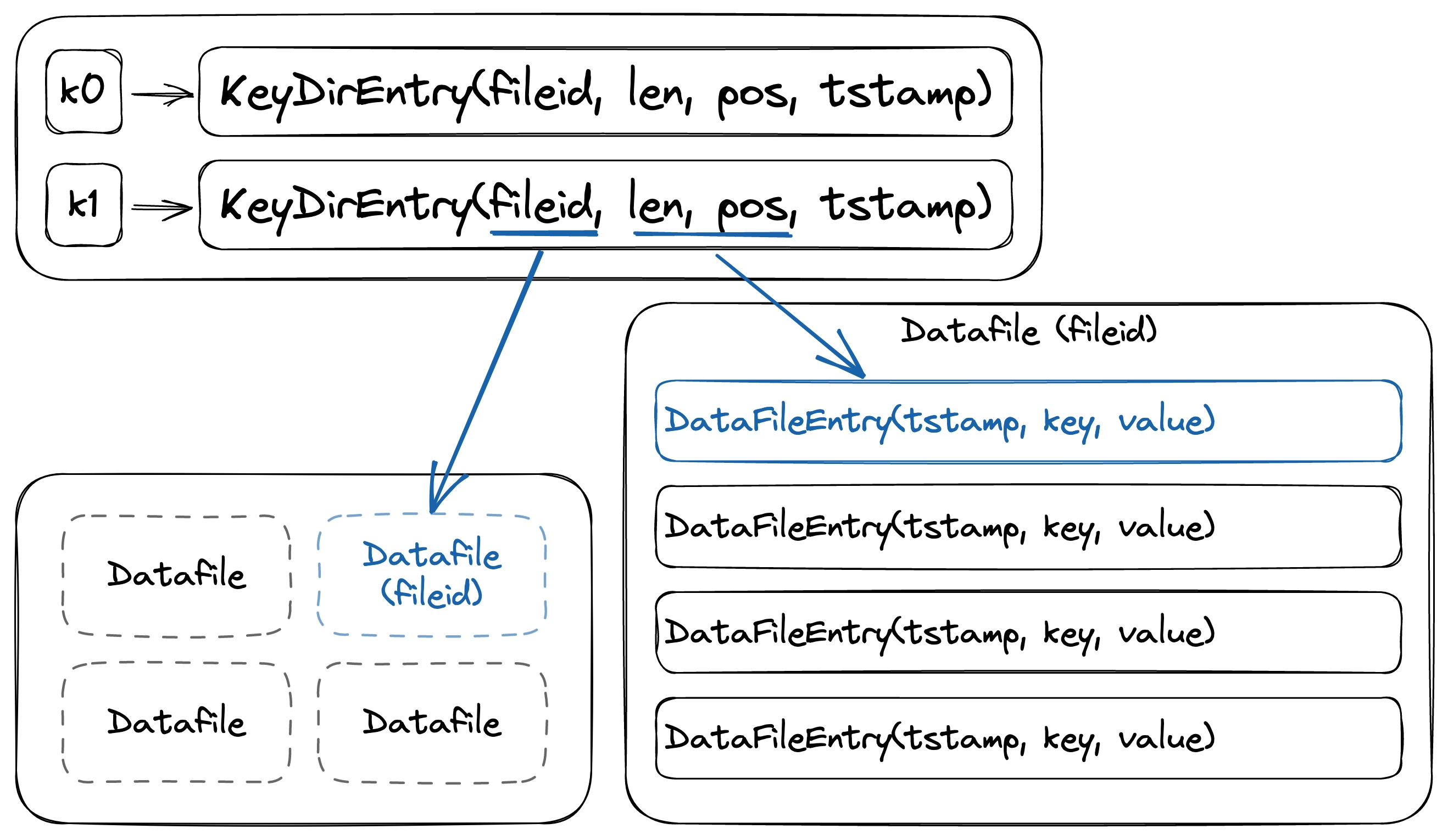
Bitcask's KeyDir
To retrieve the values that we’ve appended using LogWriter, we need a way to keep track of them. We accomplish this by using an in-memory hash table that stores all the keys and maps each to an offset in one of the data files. Here, we use a structure called KeyDirEntry, which contains the file identifier, the position of the data file entry in that file, and some other details like the timestamp.
type KeyDir = HashMap<Bytes, KeyDirEntry>;
struct KeyDirEntry {
fileid: u64,
len: u64,
pos: u64,
tstamp: i64,
}
Operations on Bitcask
Believe it or not, that’s all the structures we need to implement the core components of Bitcask! Let’s dive into the operations defined for Bitcask. Our implementation of Bitcask uses the KeyValueStorage trait, an interface for a thread-safe key-value store. This interface enforces implementors to maintain a consistent view of the shared storage from multiple threads.
trait KeyValueStorage: Clone + Send + 'static {
type Error: std::error::Error + Send + Sync;
fn set(&self, key: Bytes, value: Bytes) -> Result<(), Self::Error>;
fn get(&self, key: Bytes) -> Result<Option<Bytes>, Self::Error>;
fn del(&self, key: Bytes) -> Result<bool, Self::Error>;
}
It’s important to note that the trait extends Send, indicating that any implementation must be thread-safe. Despite the simplicity of the individual components of Bitcask, optimizing their performance in a multi-threaded environment presents a challenge.
To better understand the design, a high-level implementation of the basic operations will be presented. This will lay the groundwork for further optimization and improvement. For now, let’s imagine that we have some structure called BitcaskContext that encapsulates all the states we need to operate.
Setting a key-value pair
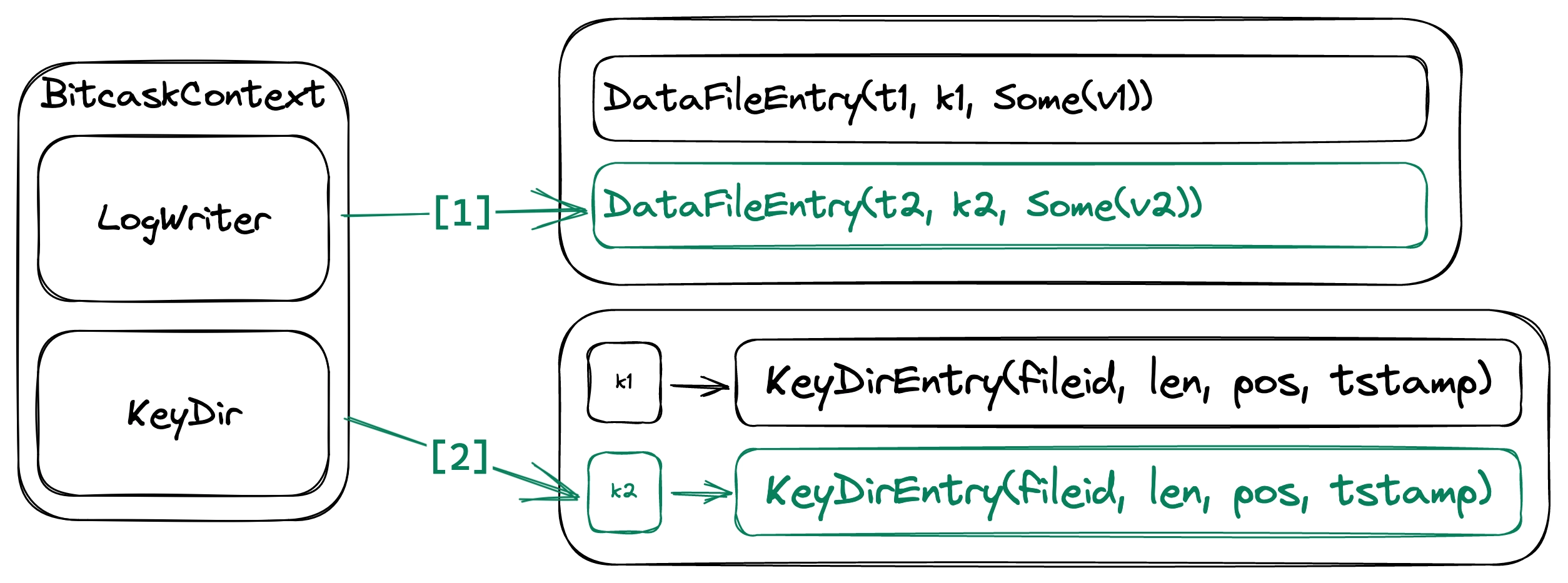
Inserting a key-value pair
This operation assigns a value to a key and overwrites any previous value. This is done by appending into the active data file, then updating the KeyDir and overwriting any existing KeyDirEntry. Setting a key-value pair is inexpensive as it involves only one disk write and a few in-memory changes. Besides, we don’t have to perform any disk seek when appending to the end of the active file.
It’s important to note that if this operation overwrites an existing KeyDirEntry, the corresponding DataFileEntry is not deleted from the data files. Moreover, entries created by this operation will always have Option::Some as their value.
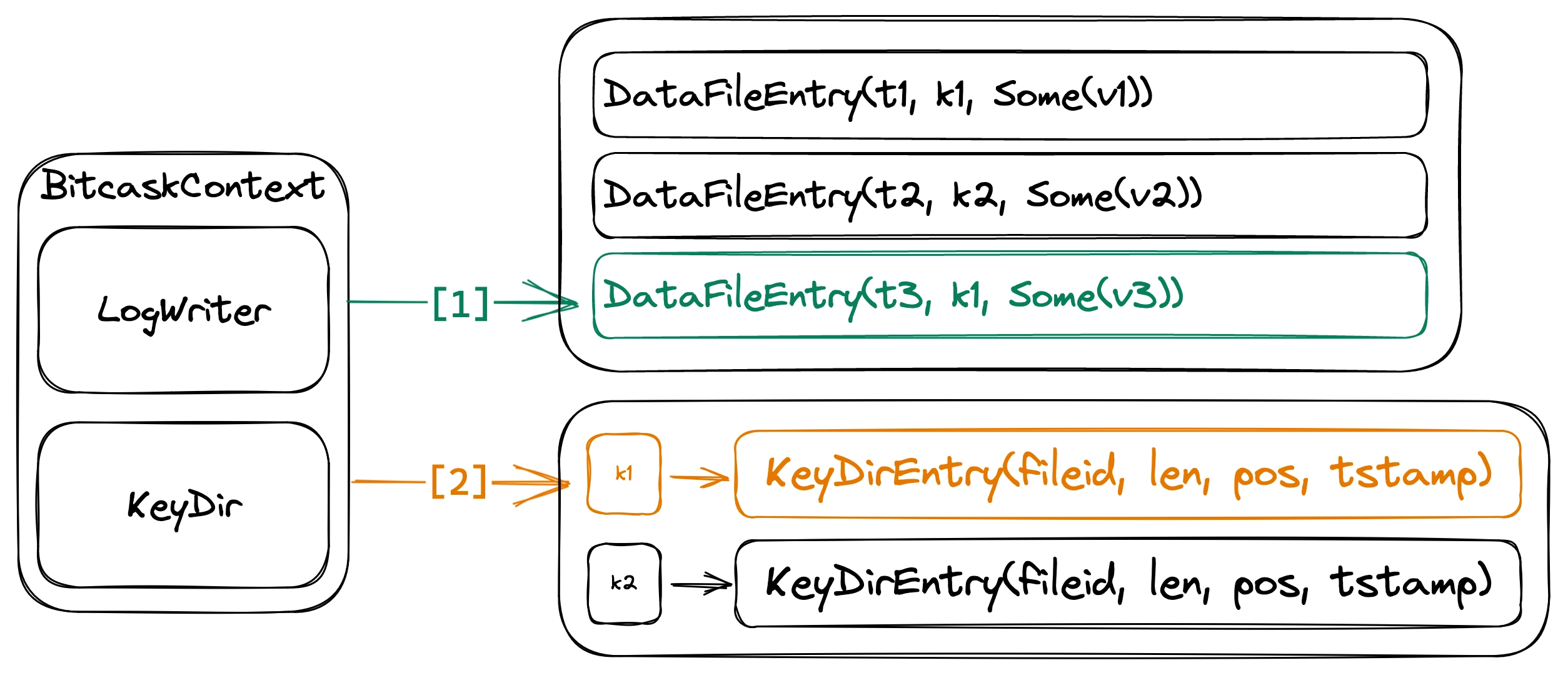
Updating a key-value pair
Deleting a key-value pair
This operation removes a key returning true if it exists, otherwise returning false. This is done by appending into the active data file, then removing the KeyDirEntry located at the matching key in the KeyDir if it exists. Deleting a key-value pair has the same performance characteristics as setting one.
Like when we set a key-value pair, if this operation successfully removes a KeyDirEntry, the corresponding DataFileEntry is not deleted from the data files. The difference is that entries created by this operation will always have Option::None as its value.
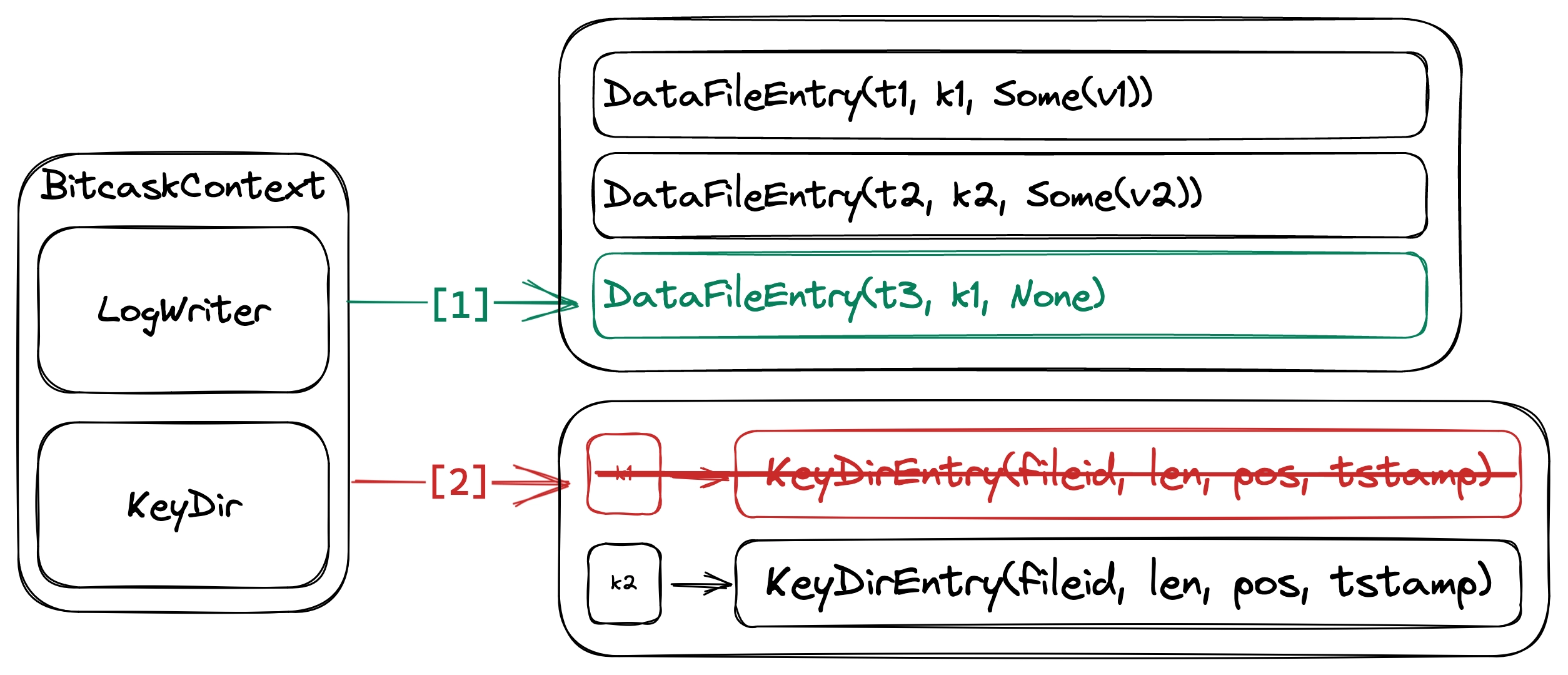
Deleting a key-value pair
Reading key-value pairs
This operation returns a key’s value if it exists. This is done by finding the KeyDirEntry at key in the KeyDir, then, if the entry is found, deserialize the bytes in the range [pos, pos + len) to get the DataFileEntry.
All mutating operations are performed by first appending an entry to the data file, then updating KeyDir to reflect the new state. We warrant that these two steps are performed atomically and in order. By making writes on disk always happens before any modifications are made on KeyDir, we can ensure that every entry in KeyDir points to a valid DataFileEntry. Under this guarantee, we can be confident that LogReader won’t misbehave when using memmap2.
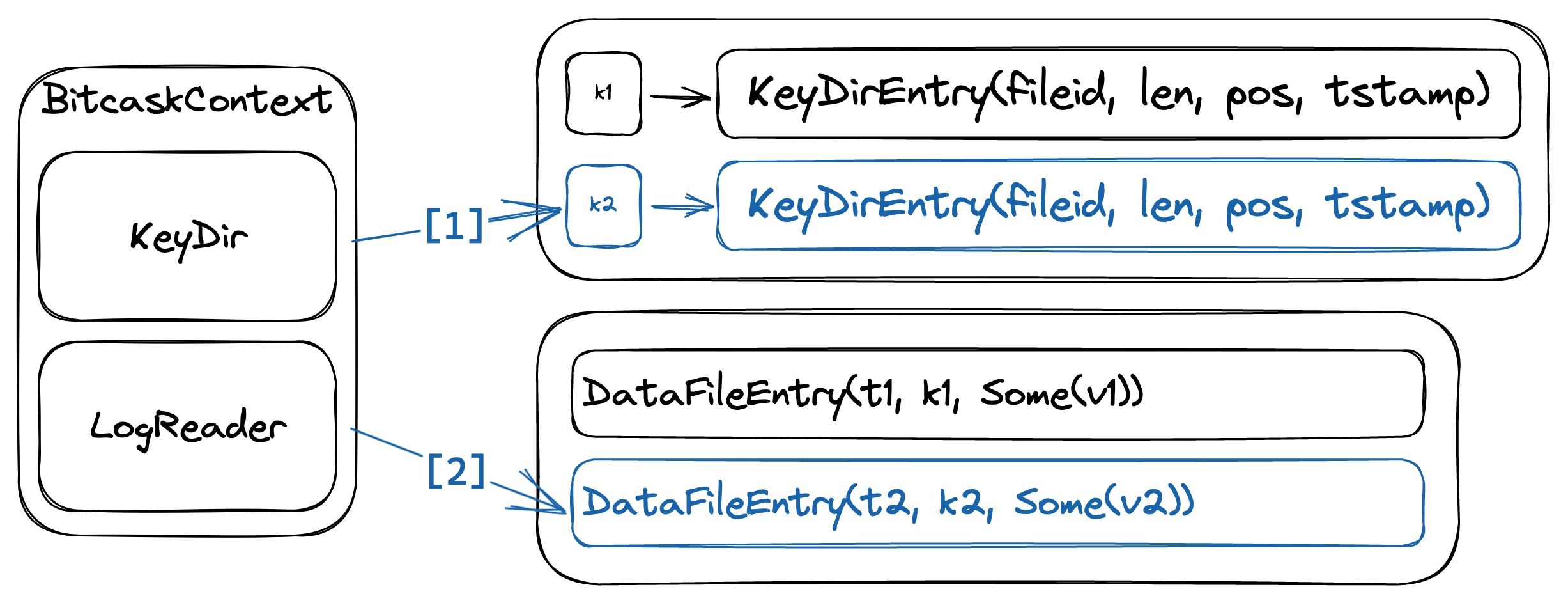
Reading a key-value pair
Storage compaction and recovery
If you realize, we leave dangling data entries when we overwrite or delete a key, which wastes lots of disk space. To reclaim disk space, Bitcask periodically merges data files and ensures they represent the same key-value pairs as before the merge.
This process starts by creating a new active data file. We then iterate over all the KeyDirEntry in KeyDir and copy each corresponding DataFileEntry onto the new file. After each time we successfully copy an entry, we update KeyDirEntry to point to the position of the new DataFileEntry in the active data file. Once we finish, we end up with data files containing only live keys, and all other data files can be safely deleted.
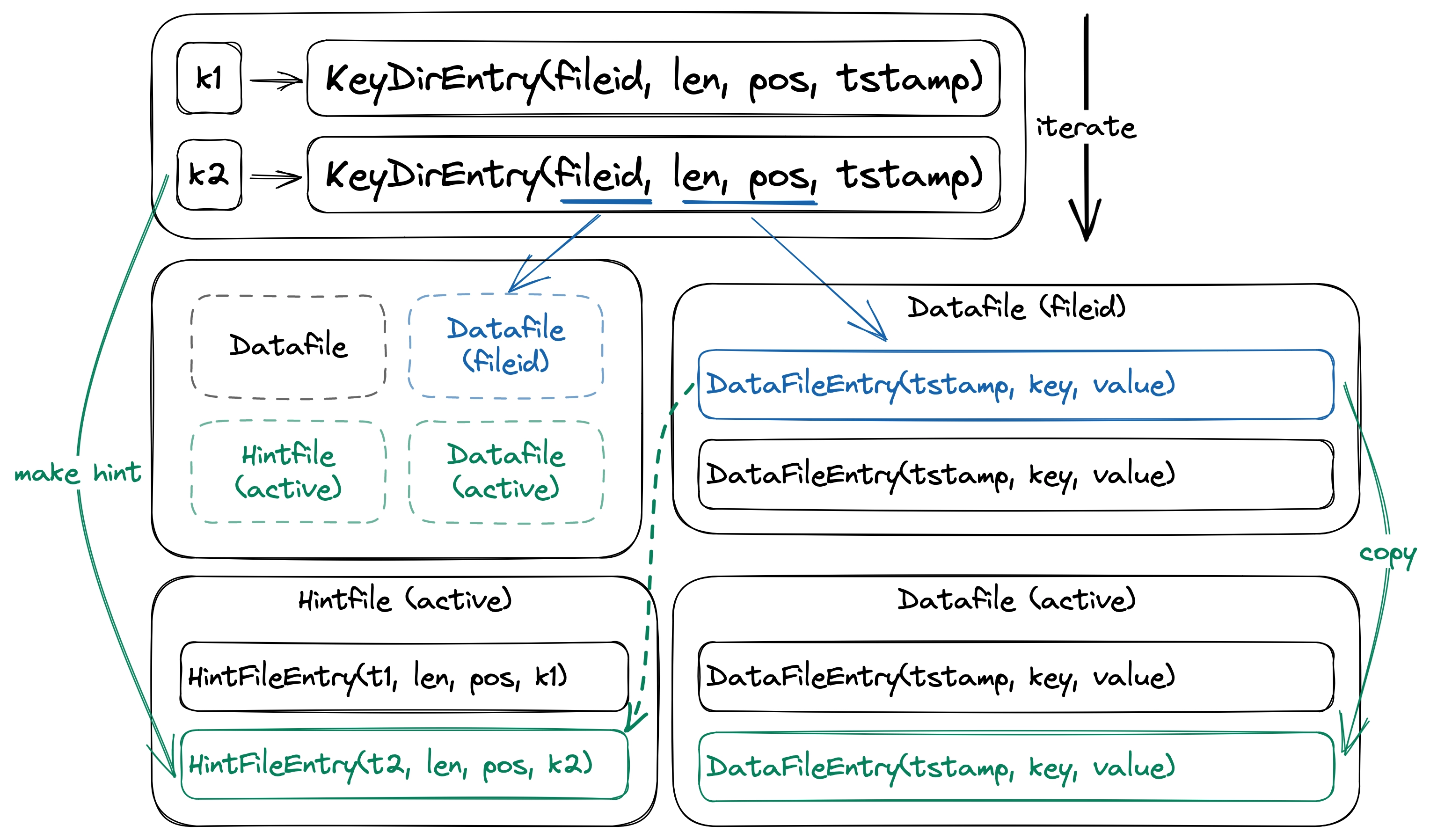
Merging data files
Bitcask introduces hint files, which are snapshots of the KeyDir on disk and behave similarly to data files, to help with boot time. As a result, we don’t have to read irrelevant data because hint files only contain data of live keys. Hint files are created each time we perform a merge and have the same id as the merged data file. While booting up, Bitcask will look for existing data files and hint files in the directory and try to recover itself. This involves going through the data files or hint files in order, reading the entries from each file, and updating the KeyDir for each entry we encounter. The structure for the hint file entry also uses serde and can be appended to the hint file using LogWriter.
#[derive(Serialize, Deserialize)]
struct HintFileEntry {
tstamp: i64,
len: u64,
pos: u64,
key: Bytes,
}
The philosophers are dining
By now, you should have known about the inner working of the components of Bitcask and how they cooperate to maintain the state of the key-value store. But how do we design a thread-safe structure that can implement KeyValueStorage?
Coarse-grained locking
Assuming that BitcaskContext encapsulates all Bitcask states, we ensure that access to this structure is thread-safe. The simplest way to make any structure thread-safe is to wrap it in an Arc<Mutex<T>>:
- The
Arc<T>stands for “Atomic Reference Counting” which means an atomic integer is used to count how many references to the inner structure are being handed out. Once the count reaches zero, it’s safe to delete the referenced data because we’re guaranteed that no other threads will ever access it. - The
Mutex<T>stands for “Mutual Exclusion” which ensures only one thread can read from or write to the inner state at any given time.
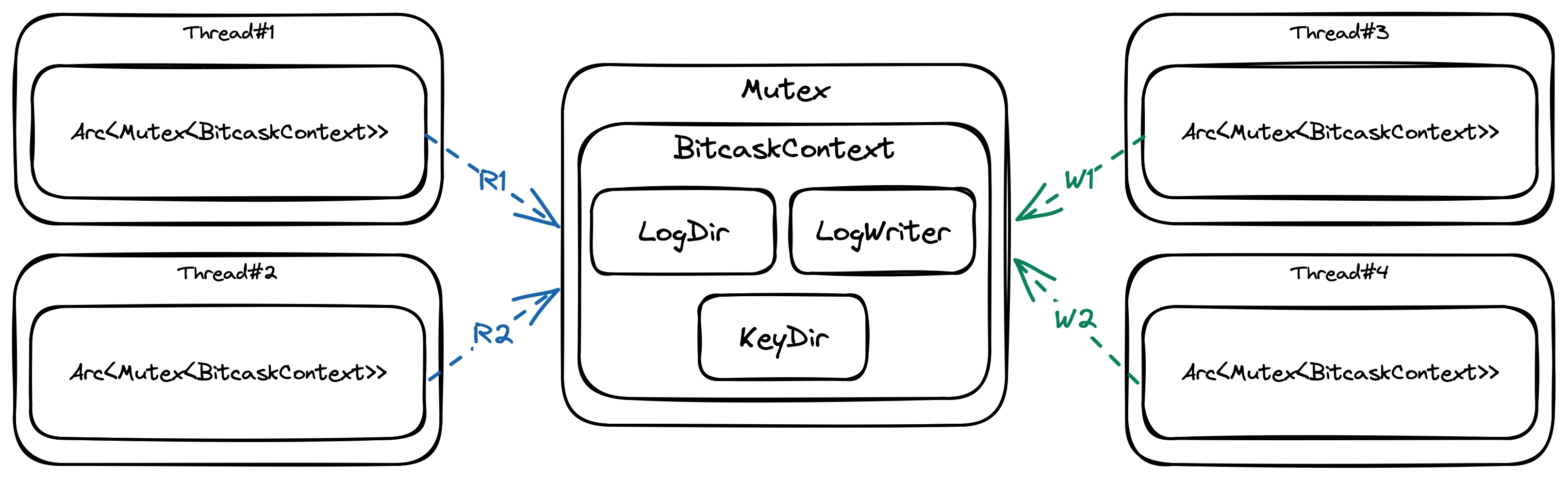
Coarse-grained locking design
Using Arc<Mutex<T>>, multiple threads can share a Mutex<T>, and the underlying T to be accessed safely through the Mutex<T> without the risk of race conditions. Imagine four threads simultaneously trying to read from and write to the store. One of the threads will acquire the lock while the other has to wait until the lock is released. In other words, every request has to wait for the previous request to finish before it can start. Under heavy load, this causes high latency, and incoming requests might become unresponsive if the thread handling that request can’t acquire the lock.
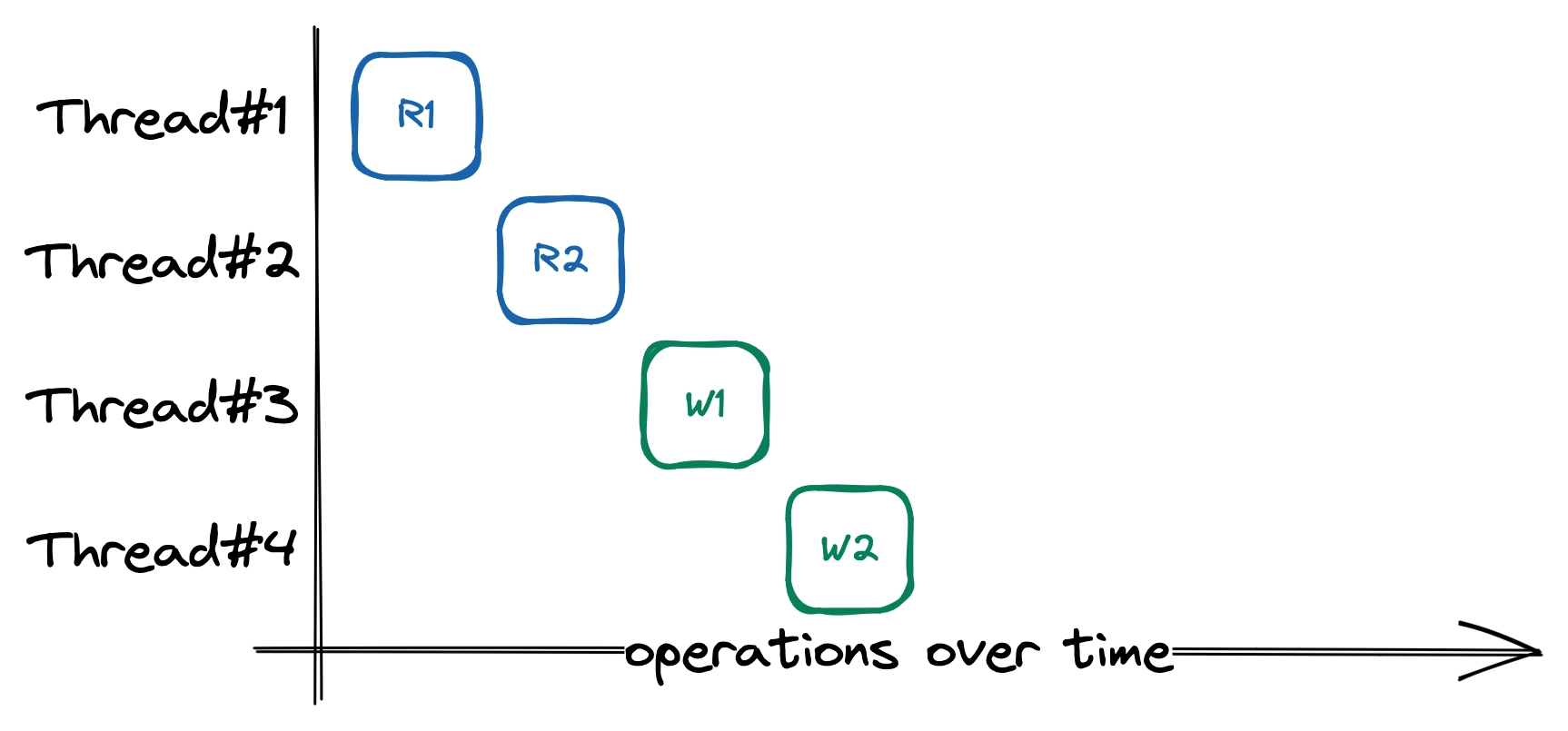
Order of executions (course-grained locking with Mutex)
The situation above can be better by switching to a RwMutex to distinguish between read and write operations. We know that reads won’t modify states, so they can’t interfere with the execution of other threads. Thus, reads can happen in parallel with each other, and states are only mutually excluded while we’re modifying them.
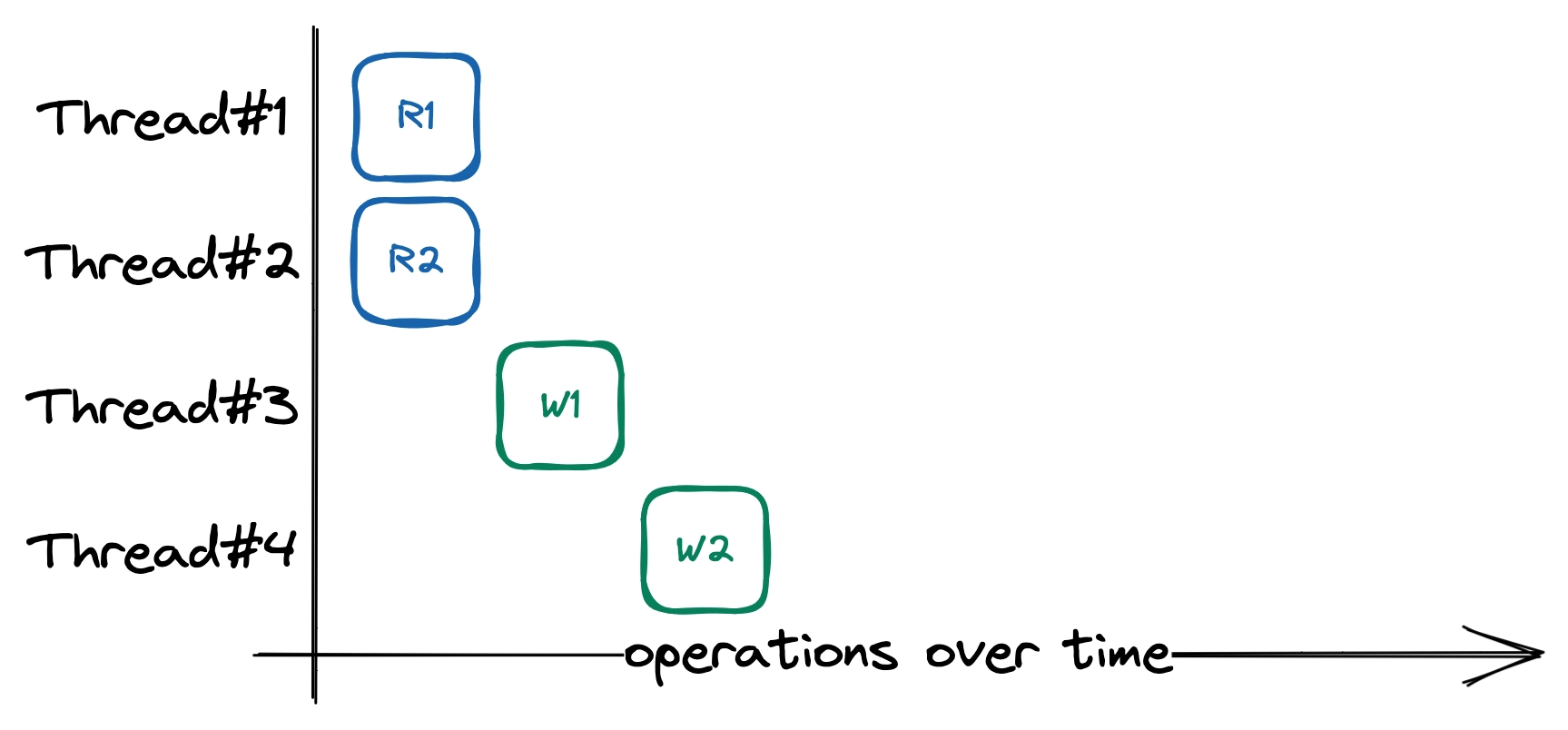
Order of executions (coarse-grained locking with RwMutex)
Fine-grained locking
While a RwMutex can help a lot with parallelizing accesses to the key-value store, we can still do better. Our current design places a Mutex/RwMutex around every state, but the writer and readers use different sets of components to perform their functionalities and share only a few of those states.
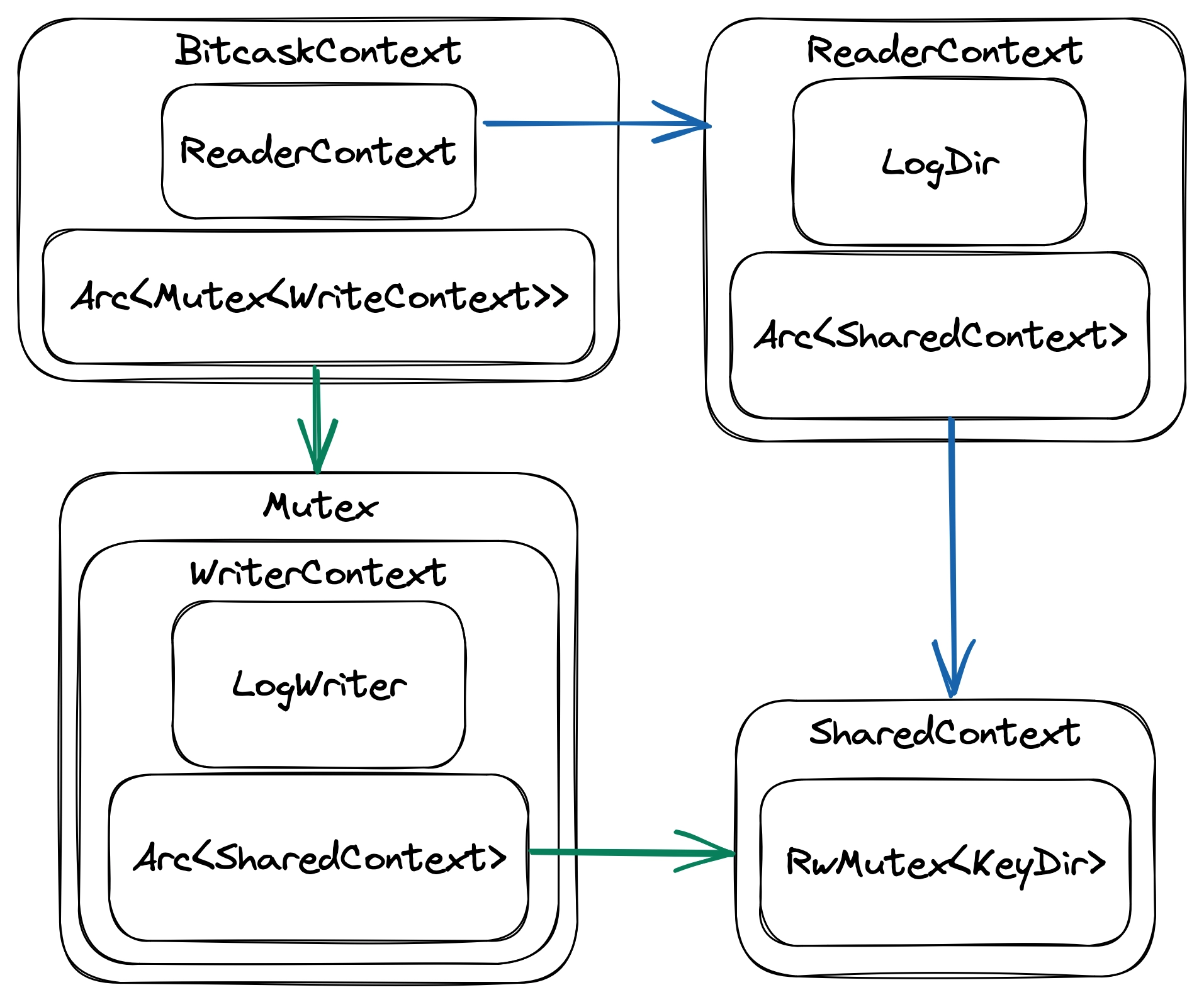
Fine-grained locking design
Once we have separated states based on their functionalities, the writer and readers only share the KeyDir and nothing else. Technically, we’re still sharing the directory containing the data files. But, because the writer never modifies entries that were previously appended, we can’t have data races on the data files. Therefore, we’re not concerned with keeping the data files thread-safe when there’s only one writer.
BitcaskContext now provides mutually exclusive access to a shared WriterContext while having its own ReaderContext. This means we’re not sharing the readers’ states, and multiple LogDir can be created to open the same set of files. Both WriterContext and ReaderContext now share access to the same KeyDir through SharedContext. With this design, the writer and readers only have contention on the KeyDir, and the critical region won’t include disk operations.
Lock-free reads
One benefit from structuring our data this way is we can now control the performance characteristics by changing how KeyDir is implemented. Rather than RwMutex<HashMap>, we can use SkipMap from crossbeam-skiplist to have lock-free concurrent access to KeyDir. Consequently, readers can’t be blocked by the writer and can’t prevent the writer from progressing.
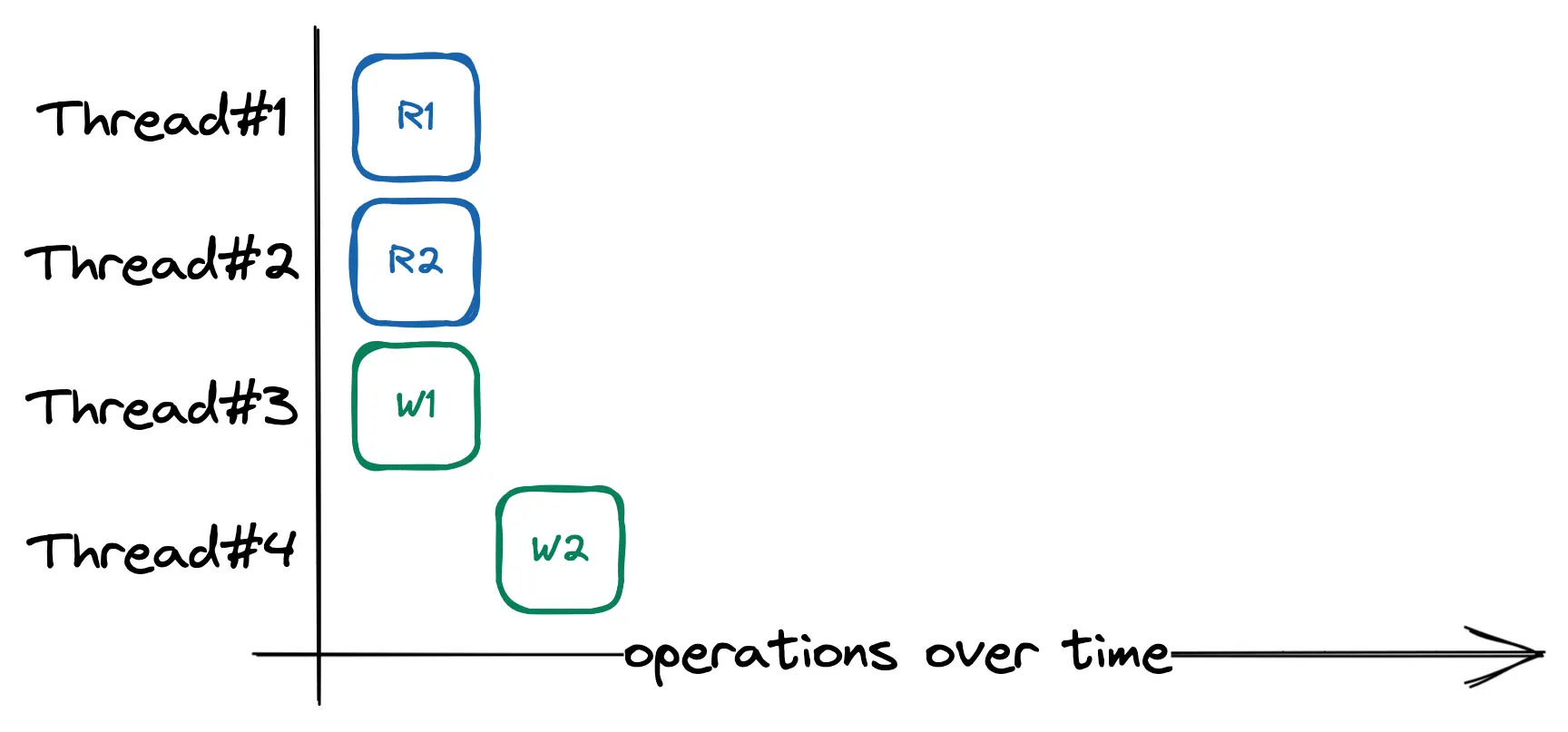
Order of execution (lock-free readers)
Afterword
Bitcask achieves high throughput and low latency by minimizing the number of disk accesses and performing little to no file seeking. It stores data in a commit log, which enables fast recovery and ensures that no data is lost after a crash. Bitcask’s simple code structure and data format make it easy to understand and implement. In addition, the core design of Bitcask makes it easy to parallelize and reason about when in a concurrent environment. One drawback is Bitcask requires a significant amount of RAM that grows with the key space because KeyDir has to store every key in memory.
In this post, we demonstrated both the low-level and high-level of our Bitcask implementation and showed how we optimized it for a multi-threaded environment. To see more of the code, you can visit https://github.com/ltungv/bitcask. If you’re interested, the repository also contains an implementation of RESP for our key-value store to communicate with the outside world.